
飞书杀疯了!AI生成工作流上线,一句话搞定业务自动化
目前已经提前拿到内测资格,并进行一些案例的测试。体验下来真就一个字“丝滑”,像Coze工作流是需要我们开发者手动搭建一个又一个节点。 花费的时间不说,还要学习Coze的每个板块的使用,但飞书多维表格中即将上线的就是AI生成工作流:“一句话让...
目前已经提前拿到内测资格,并进行一些案例的测试。体验下来真就一个字“丝滑”,像Coze工作流是需要我们开发者手动搭建一个又一个节点。 花费的时间不说,还要学习Coze的每个板块的使用,但飞书多维表格中即将上线的就是AI生成工作流:“一句话让...
那么今天,再给大家分享一个近期刚刚兴起的赛道,那就是AI小佛陀漫画。大家可以看下面的图片,基本都是近期刚刚起号,而且数据都比较好。 再看另外一个账号,数据也很稳定。 之前分享过一期星座漫画,跟这个十分相似,但是周期太短,流量入池快,出池也快...
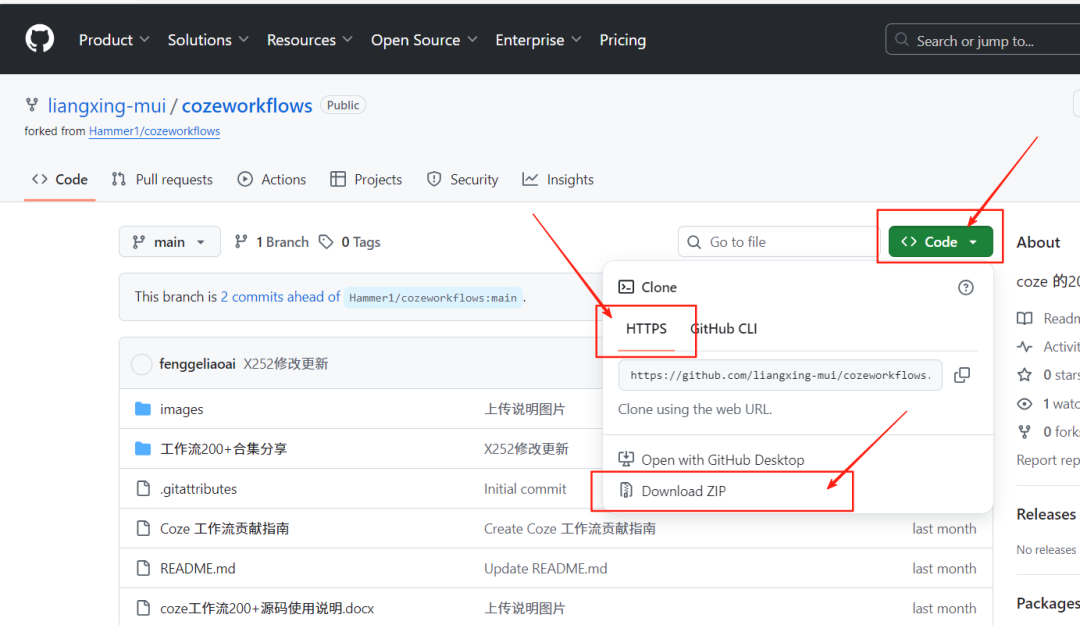
GitHub上竟然蹦出了一个神仙级的开源项目,200多款热门的扣子工作流,统统免费开源!是的,你没听错,免费!那些曾经卖几十到上千的工作流,今天一分钱都不值,而这些免费的工作流不但数量多,而且每一款都是精心打磨,绝对是精品。 这是扣子工作流...

现在是AI编程时代,什么都可以用AI来开发了,但一个正儿八经的项目还是需要很多考量的。所以开发的第一禁忌是从0开始造轮子,正确的打开方式是直接拿别人跑通的项目来改。话虽这么说,对小白来说这也很难,1是要重新理解别人项目的逻辑,2是改功能很容...
 villain
villain